 Geographic Fault Tolerance for VoIP Carriers is a hot topic. The dream is to offer a telecom service that functions properly, even if half of the equipment is detonated.
Geographic Fault Tolerance for VoIP Carriers is a hot topic. The dream is to offer a telecom service that functions properly, even if half of the equipment is detonated.
Fortunately, a VoIP Carrier far more likely to experience a simple network outage due to backhoe fade, or lose a building due to flooding, than they are to be attacked by gamma rays.
Reliability is a key goal of professional VoIP Service Providers. In February 2012, the United States' FCC made new rules that require VoIP providers to report 30-minute outage that affects 911. Simply doing routine router upgrades could create that kind of outage in many networks.
Yet, the current state of the art for VoIP Service Providers is pitiful. Let's be clear: certain core parts of the network may function perfectly. For examples, Metaswitch and BroadSoft, both have commendable geo-redundancy mechanisms in the core. They both work, and can provide good performance for customers attached to those platforms.
But on the access network, where SIP Phones (such as the PolyCom SoundPoint IP 650), ATAs (such as the Linksys SPA-2102), and IADs (such as the Cisco IAD2432 and Adtran TA908e) contact the VoIP Carrier network, the problem is much harder. While BroadSoft and Metaswitch need only integrate two physical VoIP devices to make a single functioning service for geo-redundancy, the access network requires cooperation among tens of thousands of distinct devices.
A key part of the problem is that geo-redundancy requires each access device to have the ability to contact multiple SIP servers. Typically, each SIP server is a Session Border Controller, such as the Acme Packet NN4500 or the Metaswitch Perimeta. And each of these SBCs has an address to which SIP Access devices may send SIP packets to get VoIP service.
Therefore, with two sites, the SBC at Site A has one IP address, e.g., 1.2.3.4, and the SBC at Site B has another IP address, e.g., 5.6.7.8. And so the SIP Access device has to choose among these two devices to send its SIP traffic to.
Anycast VoIP
Why two separate IP addresses? Why not just have a single address, like Level(3)'s DNS server 4.2.2.2? In the case of DNS, each request is atomic, and independent. If request #1 goes to 4.2.2.2 in Chicago, and then request #2 goes to 4.2.2.2 in Las Vegas, then everything will be fine.
But with SIP, the access device's registration state, and dialog state, would need to be synchronized between all of the various members of the anycast group; that is, the subsequent requests from a SIP Access device are not independent. (I'm not making a claim that it's impossible to make a anycast-capable SBC. I would expect that it is possible to do so. But they're not for sale today.)
Sunny Day Scenario
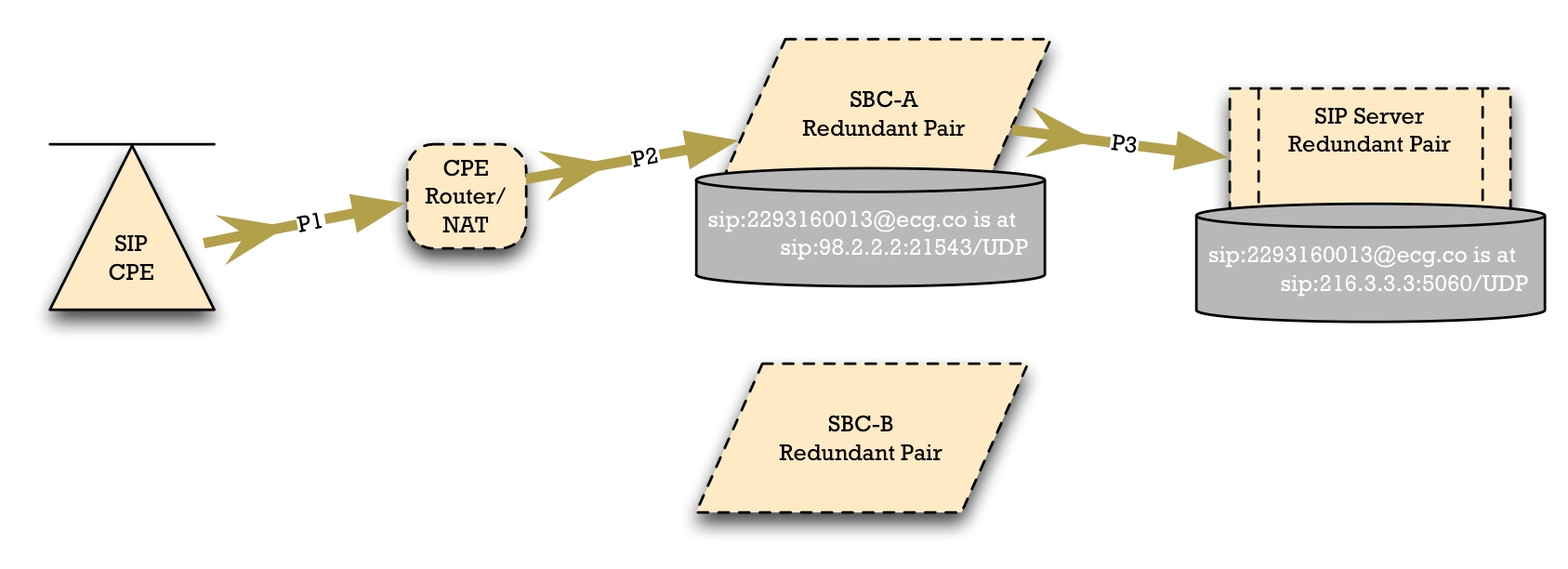
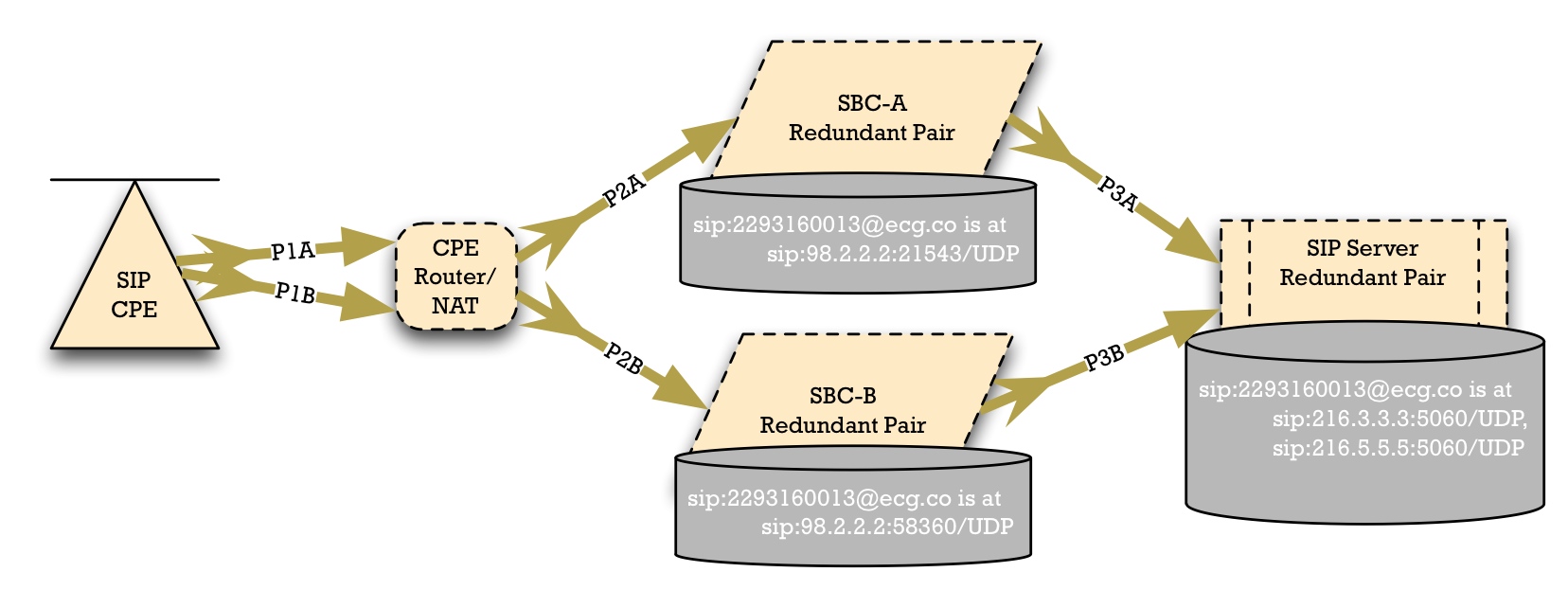
Typically, then, we have this sunny day scenario, in which we have SBC-A and SBC-B at two different sites. In the core, we have some kind of synchronized SIP Server, but on the edge of the access network, we have two different SBCs.
The Access Device selects SBC-A. And note that, in general, we have to allow for a NAT or Firewall, shown here as "CPE Router/NAT". The Access Device should use NAPTR or SRV to locate the SBCs. Through this mechanism, it can be told that SBC-A is the preferred SBC to use.
SBC-A has a local registration database. In this case, it's recording that the SIP Address of Record (AoR) "sip:2293160013@ecg.co" is reachable at the Contact "sip:98.2.2.2:21543".
Site A Fault
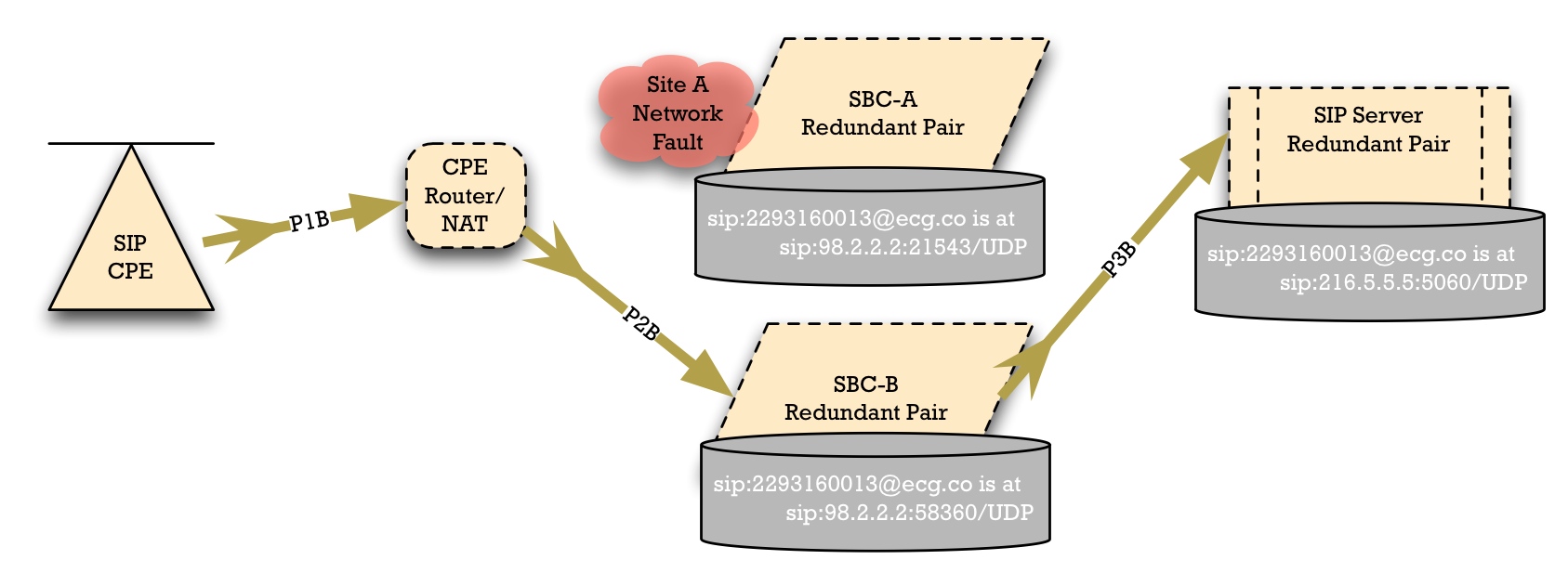
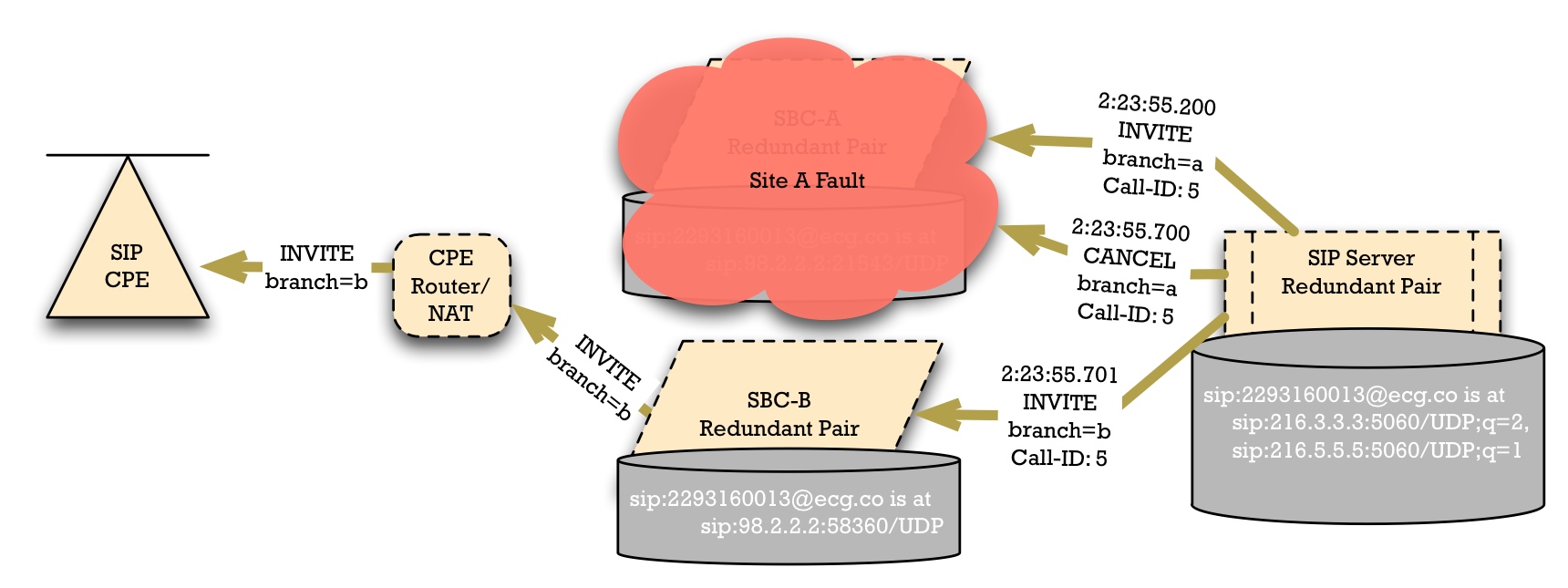
When Site A has a fault, the SIP Access Device detects this. The standard method of detection is that when the SIP access device refreshes its registration, it will fail to get a reply. It may retry a few times, and then eventually it will abandon Site A's SBC. It will use the "higher cost" entry from the DNS SRV result, causing it to failover to SBC-B.
When it does so, the NAT device may create a new "pinhole"; this can be observed by the port numbers. SBC-B records this pinhole port number, so that the same SIP AoA "sip:2293160013@ecg.co" is now reachable at "sip:98.2.2.2:58360".
In the case of the best firewalls and Symmetric NAT devices, the router/NAT/firewall will create a distinct public-network-facing port number for the SIP flow to SBC-B.
Raises More Questions
This technique raises a lot of questions:
- How should failures be detected?Certainly, failures to receive several replies should trigger a failover. But what about SIP 503 responses? Or SIP 400 responses?
- What's the worst-case failover time?How long could it take a SIP access device to detect the SBC-A outage? Will SBC-B, and the core server, be able to immediately handle the re-registration of the user population? And, if not, how long will it take the last SIP access device to re-register for service?
- Can SBC-B and the core handle the load?When SBC-A fails, many SIP Access devices (30,000 or more sometimes) have to re-register with SBC-B. That's a huge avalanche of registrations.
- When should the access device retry the SBC-A?Should the access device retry SBC-A on every call and every re-registration? Or should it stick with SBC-B for some time?
- What happens to phone calls during the failover process?Are existing calls dropped? And what about a new call going toward the SIP Access Device, while the failover-recovery-reregistration is occurring?
- What happens to subscription state?For features like Message Waiting Indicator (MWI, e.g., simple-message-summary) or Busy Lamp Field / Line State Monitoring, the SIP Access Device generally subscribes to the data source. When it fails over to SBC-B, does it need to re-subscribe?
- What happens is SBC-B fails? Should SIP access devices immediately retry SBC-A?
The frightening fact is that every SIP device and software version may answer these questions differently. That is: Adtran, Linksys SPA, Cisco IOS, Polycom, Audiocodes, and others may handle these questions differently.
Would replicating NAT contacts in the SBC help?
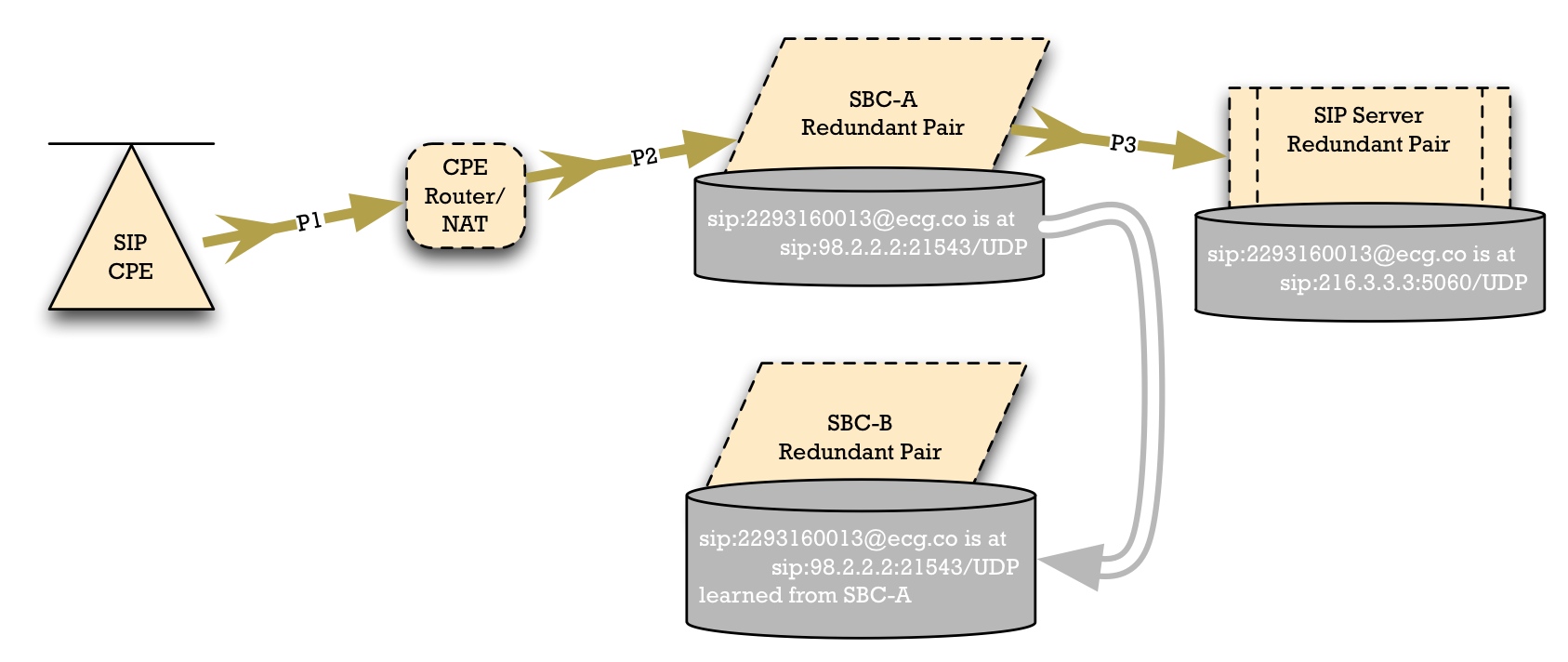
We might be tempted to replicate the data from SBC-A's registration cache over to SBC-B. Thus, when an SBC-A fault occurs, calls going toward the SIP Access Devices could route through SBC-B, down to the SIP phone.
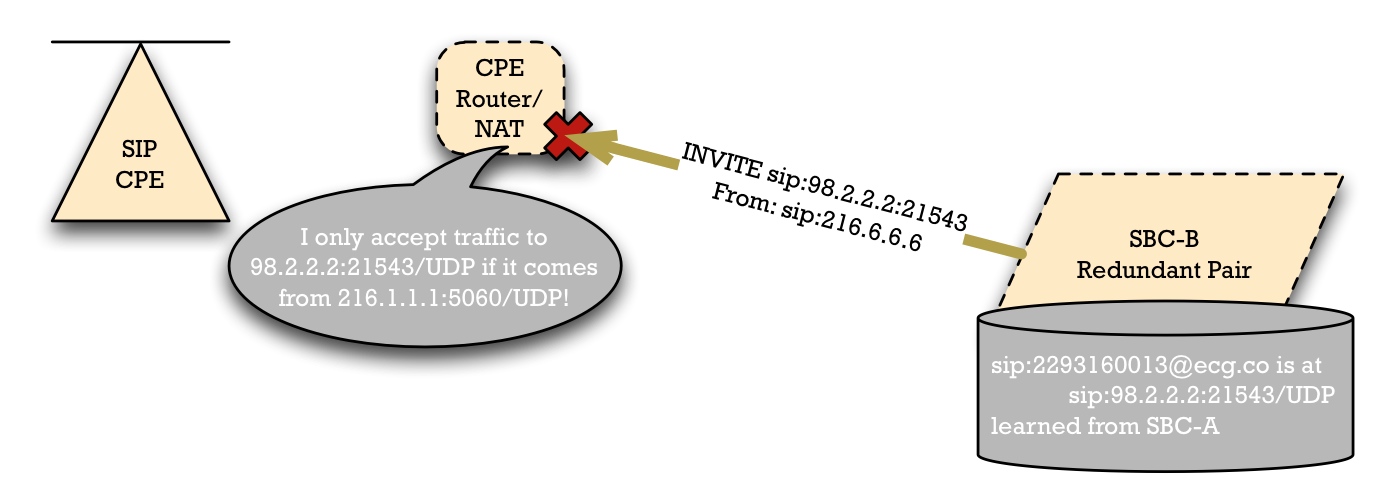
Unfortunately, this won't work in many cases. The CPE router/NAT/firewall wouldn't allow the SIP packets from SBC-B to reach the SIP Access device. The NAT device will know that there's a single public-side IP address and port number -- i.e., SBC-A's IP address -- which is allowed to send packets to the pinhole created for it. So if SBC-B tries to send a packet to 98.2.2.2:21543, the NAT device could reasonable reject this as a possible security problem.
(This approach may have some life in specific cases under highly-controlled scenarios. For example, Carl Klatsky of Comcast Cable reported at SIPNOC 2012 success using an approach related to this. They solved this problem by having their SIP Access Device CPE vendor modify its stack to allow the SIP messaging from another IP address other than the IP address they had registered to.)
A better approach: SIP Parallel Registration Redundancy
Overall, we need a better approach. This failover process that creates an outage and an avalanche of re-registration is folly.
Enter SIP Parallel Registration Redundancy. The idea is that the SIP Access Device registers through both SBCs, all the time.
This would require support at the two SIP Endpoints -- the Access device, and the core Registrar.
- SIP Access Device. The SIP Phone will need to register simultaneously with two SBCs.
- Core Server. The Core server will need to accept two registrations for each user.
So, imagining we had all this right, we could do failover in a primary/standby mode, or in a simultaneous mode.
Primary-Standby Mode Failover
In the Primary-Standby Mode of failover, a single call could be attempted through the SBC-A path first. Remember that this represents not only that primary SBC, but also the site where the SBC is, and the network path from the SBC down to the SIP Access Device.
But the very same call could be re-attempted on the secondary SBC. The secondary SBC will have a path to reach the access device, because the access device is registered with SBC-B as well.
Simultaneous Mode
SIP already has mechanisms for handling call forking. So we could do the failover using a simultaneous mode, as well. In this mode, the call is sent simultaneously through both SBC paths. If only one SBC is functioning, then that SBC will pass the call to the endpoint.
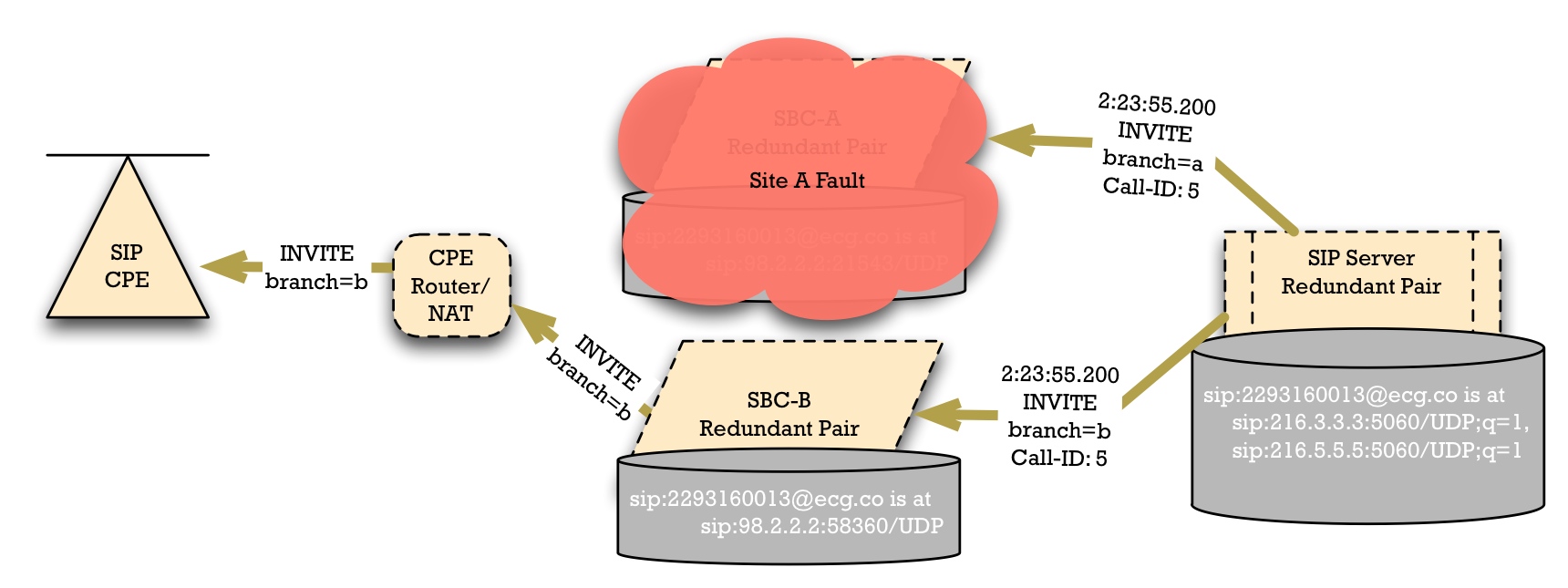
If both SBC paths are functioning in simultaneous mode, then the receiving device can differentiate between the two paths through the Via header's branch tag.
Deployment Considerations
Will all this extra SIP traffic make your network go crazy? I think not for today's network.
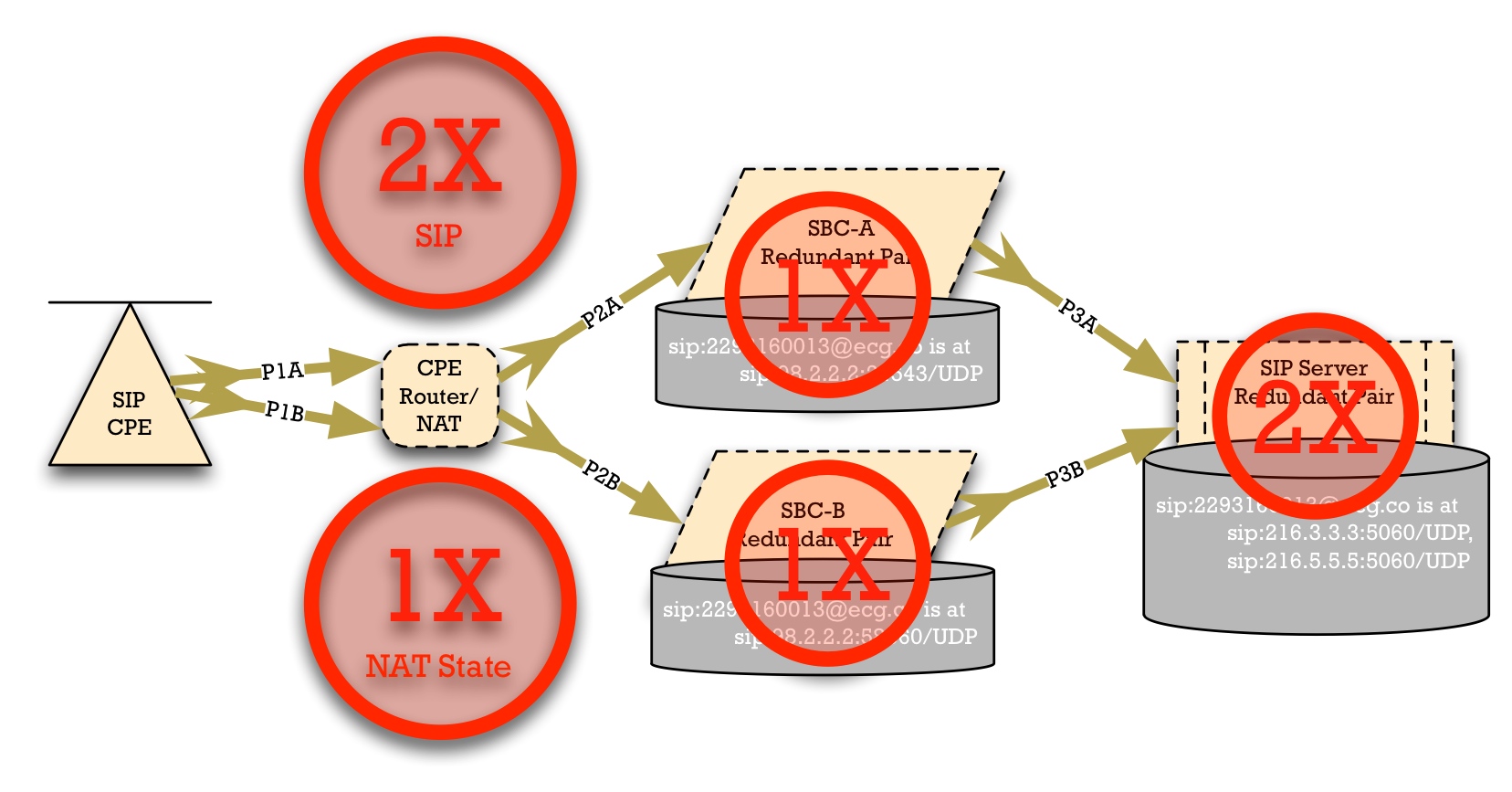
- SIP Access Device CPE.The SIP Access Device will register with two SBCs instead of just one. But this is equivalent to registering to two lines, instead of just one. Without any modifications, we know that many phones can the SIP for multiple phone lines, but they're not actually using it. And many phones currently supporting 6 lines (such as the Polycom SoundPoint IP 650) can actually support many more lines through the use of sidecars. So in many cases, the SIP endpoints have adequate CPU capacity to handle the signaling for double the SIP registrations.
- CPE Router/NAT.
- SIP Traffic. The Router/NAT device at the customer premise will handle twice as much SIP traffic as it would under the classic model. But this is a phenomenally low packet rate. For example, a Hosted PBX installation with 30 phones with moderate Busy-Lamp-Field/Line-State-Monitoring (BLF) and Shared-Call-Appearance (SCA), where each phone is making 1 call every 5 minutes generates only about 3 packets per second of SIP signaling. If you double that to 6 packets per second, the CPE Router is not going to have a problem.
- NAT State. Each registration path creates a "pinhole" or, as Cisco calls them, "xlate". It's a mapping allowing traffic from the public network to the private network. SIP Parallel Registration Redundancy really does not increase the NAT State requirements for router/NAT device over the legacy model. Here's why: under the current model of failover, the NAT router has to support all of the devices registered to SBC-A normally. In the case of a failover, they all re-register with SBC-B. But re-registering with SBC-B does not delete the NAT State entries for SBC-A. Therefore, if the current model of failover actually works right, the router/NAT/firewall device has support for registrations to SBC-A and SBC-B simultaneously, today.
- SBC-A and SBC-B. Parallel Registration Redundancy put no additional requirement on the SBC sites. Each site is capable of handling the entire user population regardless.In fact, this model reduces the peak workload requirement of each SBC, because it eliminates the failover avalanche that occurs when the entire Access Device population re-registers with an individual SBC site.
- Core Registrar. The core registrar would have twice as many SIP registrations to support. But SIP registrations are not a heavy workload, so doubling the number of registrations would be easily supported in all installation with which I am familiar. (And I've been in the core of the network of over 50 VoIP carriers around the world.) In fact, as in the SBC case, Parallel Registrations reduce the peak workload requirement, because it eliminates the registration avalanche.
Does this mean we need to deal with the IETF?
What I'm advocating would significantly improve VoIP Carrier reliability. Fortunately, the SIP Outbound Working Group has already standardized something like this in RFC 5626.
I didn't do anything to help SIP Outbound, and it appears a bit too heavy for my tastes. For example, SIP Outbound requires a small change in the SBC, whereas my idea of using SIP only does not. (Acme Packet reports that they do support SIP Outbound.) But SIP Outbound gets the job done, and improves on my ideas in some ways.
Since the RFC is already done, let's use it.
+---------+
|Registrar|
|Proxy |
+---------+
/ \
/ \
/ \
+-----+ +-----+
|Edge1| |Edge2|
+-----+ +-----+
\ /
\ /
----------------------------NAT/FW
\ /
\ /
+------+
|User |
|Agent |
+------+
Does this really matter?
Today, VoIP users miss their incoming calls due to a site failover. And someday, someone's ambulance is going to be delayed because of a SIP Registration Avalanche.
If you have a large network and geographic redundancy on your access SBCs, then it's very likely your failover takes more than 30 minutes today. And that means every time you have a failover, you have to file with the FCC, to the best of my understanding. (I am not a lawyer).
We need to improve the performance of SIP Carrier registration failover. It will require support from the SIP Access Device vendors, and the Core server vendors.
Call Your Congressman? Call your MP?
Don't call your politician, but do call your vendors. Tell your access device vendors that you need RFC 5626 SIP Outbound support. And tell your VoIP Core server vendors you need it, too.
I originally gave this talk at SIPNOC US 2012 in Reston Virginia.
Full disclosure: Audiocodes, Adtran, and Polycom are not clients of mine. Every other vendor is.


