IP Fragmentation of SIP Messages is an enduring source of trouble.
Fragmentation of SIP traffic is a problem on the rise. It appears when everything has been working fine, and seemingly without cause, some SIP messages are lost in the network. The result is a frustrating scenario where some SIP messages are delivered fine, but others are not.
To explain SIP fragmentation, let's start at the beginning: Layer 2. Every link on an internet has a Maximum Transfer Unit (MTU) size which determines the maximum size of a packet that can traverse the link, in bytes. For Ethernet, this is often 1500 bytes. This means that no one Ethernet frame -- and therefore one packet of data -- can be transmitted across a standard Ethernet network that is larger than 1500 bytes. The duty of the Ethernet interface is to transmit only frames that meet this standard.
However, many applications need to send more data than this in a message. So the Operating System must accommodate both the application's need for large messages, and the network's requirement to send packets of a limited size. How is this done?
Basic Internet Protocol has a standard for fragmenting messages so they fit inside the MTU. For example, with an MTU of 1500 bytes, a single 2500 byte SIP message can fit in two frames, or IP datagrams: one fragment may have 1500 bytes, and the remaining 1000 bytes (plus some bytes for headers) will be in the second fragment.
All the King's Horses & All the King's Men
Fragmentation is fairly cheap for the fragmenter, but reassembling the fragments when they arrive is a fairly expensive operation. Simon Dredge (Metaswitch) has discussed the computational costs of re-assembling UDP fragments, arguing that the re-assembly should be done in a specialized kernel module of a Session Border Controller, rather than where the user applications run:
[T]he receiver has the tricky job of taking these seemingly miscellaneous packet fragments, deciphering them from other packets or packet fragments arriving simultaneously and piecing them back together – somewhat akin to a jigsaw puzzle – but without the aid of the picture on the lid of the box. Naturally, this process takes memory resources to store packet fragments, while waiting for their counterparts to arrive, then processing cycles to compile them . . . If fragmented packets are not successfully reassembled in a timely manner, then a retransmission will be requested or initiated, thereby further compounding the reassembly issue.
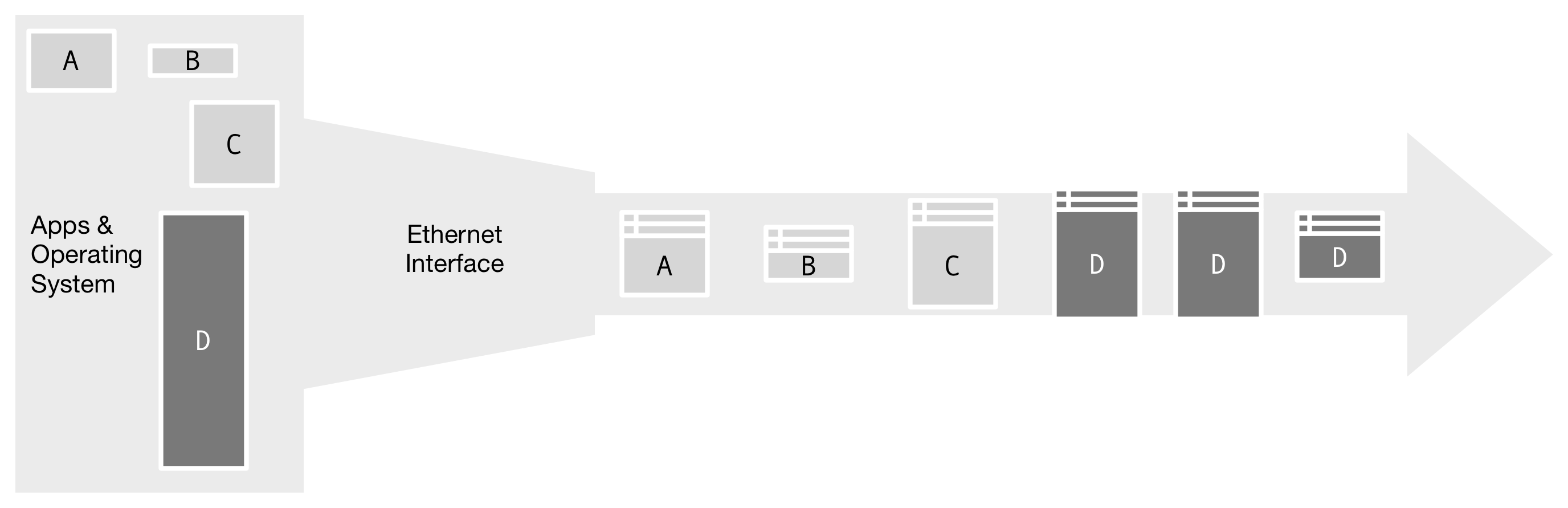 Figure 1. The Applications in the operating system send messages to be delivered as packets on a network. Smaller messages, A, B, and C, are already small enough to fit into a single frame each. But the larger message, D, is fragmented to fit into three frames.
Figure 1. The Applications in the operating system send messages to be delivered as packets on a network. Smaller messages, A, B, and C, are already small enough to fit into a single frame each. But the larger message, D, is fragmented to fit into three frames.When a large message is fragmented, the separate fragments travel as separate IP datagram packets through the network. It's possible for any one of those to be lost, but if one fragment is lost, IP has no mechanism to detect that and recover. The Internet Protocol software merely discards all the other fragments at the receiver. It depends on something else to retransmit the entire message again, on the hope that all fragments will be delivered.
Consider this analogy: This is like posting five boxes for shipment with no insurance: if four of them arrive, the mailman doesn't track down the fifth box. The recipient must determine that a box is missing and ask for its contents to be replaced.
Worse than losing a packet, the loss of a single fragment of message D wastes all the network bandwidth (capacity) that was used sending the remaining fragments. They're useless.
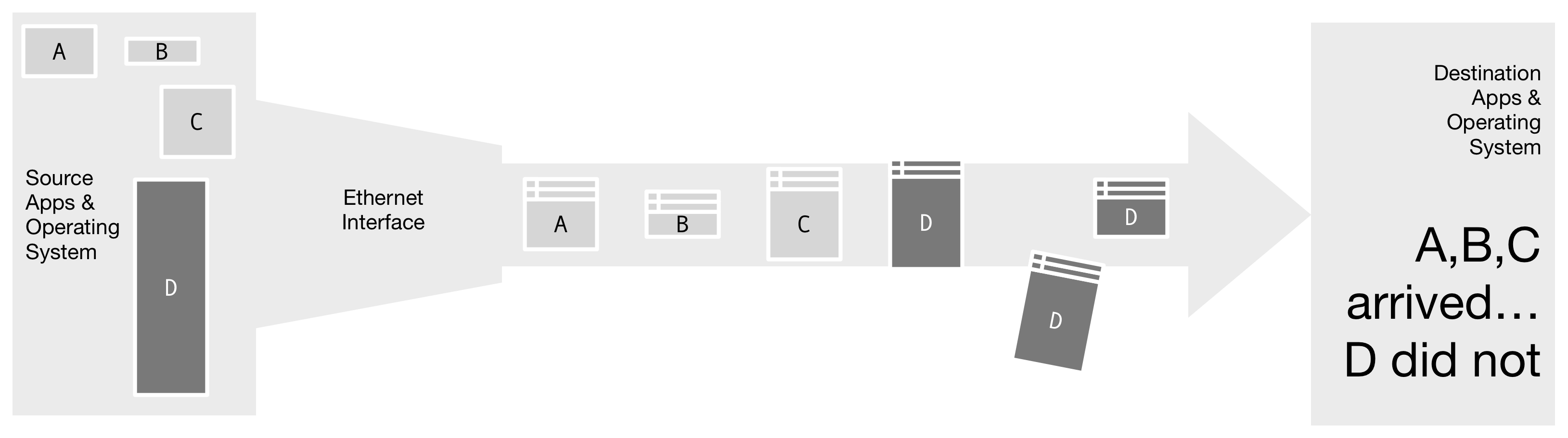 Figure 2. A single fragment of message D was lost; this results in loss of the entire message. All bandwidth consumed sending the other fragments of D was wasted. Packet loss occurs primarily due to network congestion inside router queues.
Figure 2. A single fragment of message D was lost; this results in loss of the entire message. All bandwidth consumed sending the other fragments of D was wasted. Packet loss occurs primarily due to network congestion inside router queues.TCP, which is built on top of IP, typically does not use IP fragmentation. Instead, TCP has segmentation. TCP segmentation is optimized for the case of lost segments; when one is lost, TCP slows down the transmission, and retransmits the missing segment.
Fragmentation and SIP
 Figure 3. A small SIP message, such as this NOTIFY, easily fits in a single UDP message.
Figure 3. A small SIP message, such as this NOTIFY, easily fits in a single UDP message.SIP is usually used over UDP. When the SIP messages are small, this is no problem. In fact, for normal phone calls (e.g., SIP on PSTN gateways and SIP trunks), individual SIP messages almost always fit in a single UDP message, well under 1500 bytes, and therefore no fragmentation occurs at all (See Figure 3).
But as services become more sophisticated, the size of SIP messages grows. In particular, "Busy Lamp Field", also known as "Line State Monitoring", will often be responsible for sending large data sets via SIP messages. To receive the status information on the 11 people monitored on my Polycom VVX 600, my phone receives around 11,000 bytes of data in a single SIP NOTIFY message. If I were using SIP over UDP, that would take 8 IP fragments.
 Figure 4. This Polycom VVX600 receives around 11,000 bytes of data in a single SIP NOTIFY to refresh the 11 Busy Lamp Field monitoring sessions.
Figure 4. This Polycom VVX600 receives around 11,000 bytes of data in a single SIP NOTIFY to refresh the 11 Busy Lamp Field monitoring sessions.Even basic fragmentation has been a problem for some SIP systems. Back in 2009, Eric Hernaez (SkySwitch) reported a "major vendor's" switch crashed by SIP fragments. But today, most SIP/UDP platforms support fragmentation with some reliability.
There are some approaches for reducing SIP message size in SIP. Alex Balashov (Evariste Systems) describes the challenges of reducing SIP header size in a pure-proxy system, but suggests some SIP headers you can remove in many cases. In 2009, Thomas Gelf suggested dropping unnecessary codecs, and using SIP compressed headers, like "m" instead of "Contact:"
Some vendors are opting to avoid SIP over UDP entirely. For example, Simwood's Mobile SIM Registration routinely sends SIP messages over 1500 bytes, and they adopted SIP over TCP as their standard. Yann Espanet illustrates the inefficiency of multiple fragmentation steps in his 2009 article. He points out that that Microsoft OCS didn't support SIP over UDP at all, choosing to support only TCP.
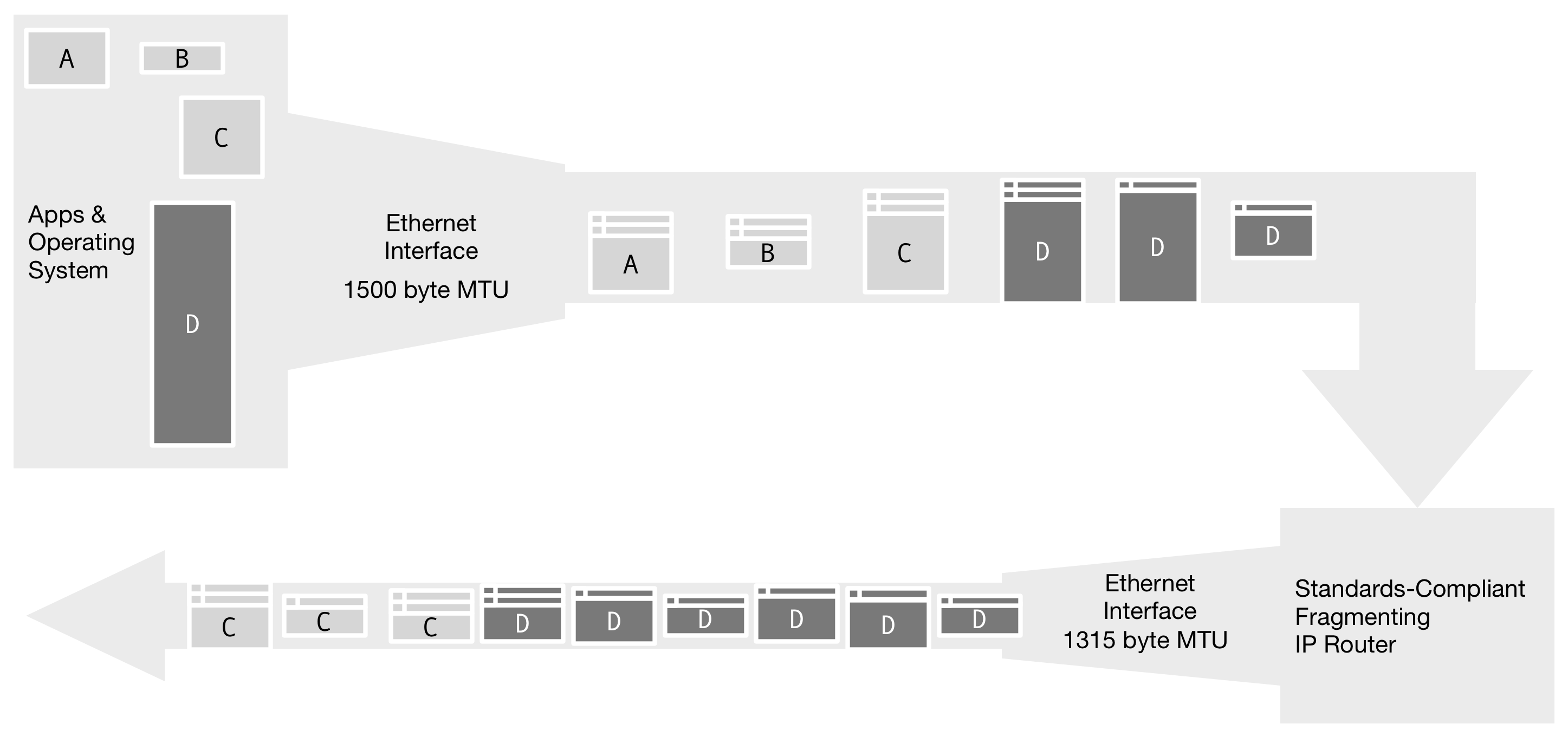 Figure 5. When the input MTU is larger than the output MTU, a standards-compliant IP router will perform fragmentation again, breaking the IP datagrams into more segments. In this example, the fragmented message D may be inefficiently fragmented further.
Figure 5. When the input MTU is larger than the output MTU, a standards-compliant IP router will perform fragmentation again, breaking the IP datagrams into more segments. In this example, the fragmented message D may be inefficiently fragmented further.SIP Fragmentation problems spiked again in 2016, when we saw numerous incidents where SIP fragmentation contributed substantially to network problems. Networks often run fine until the SIP messages grow just enough to cross the MTU boundary.
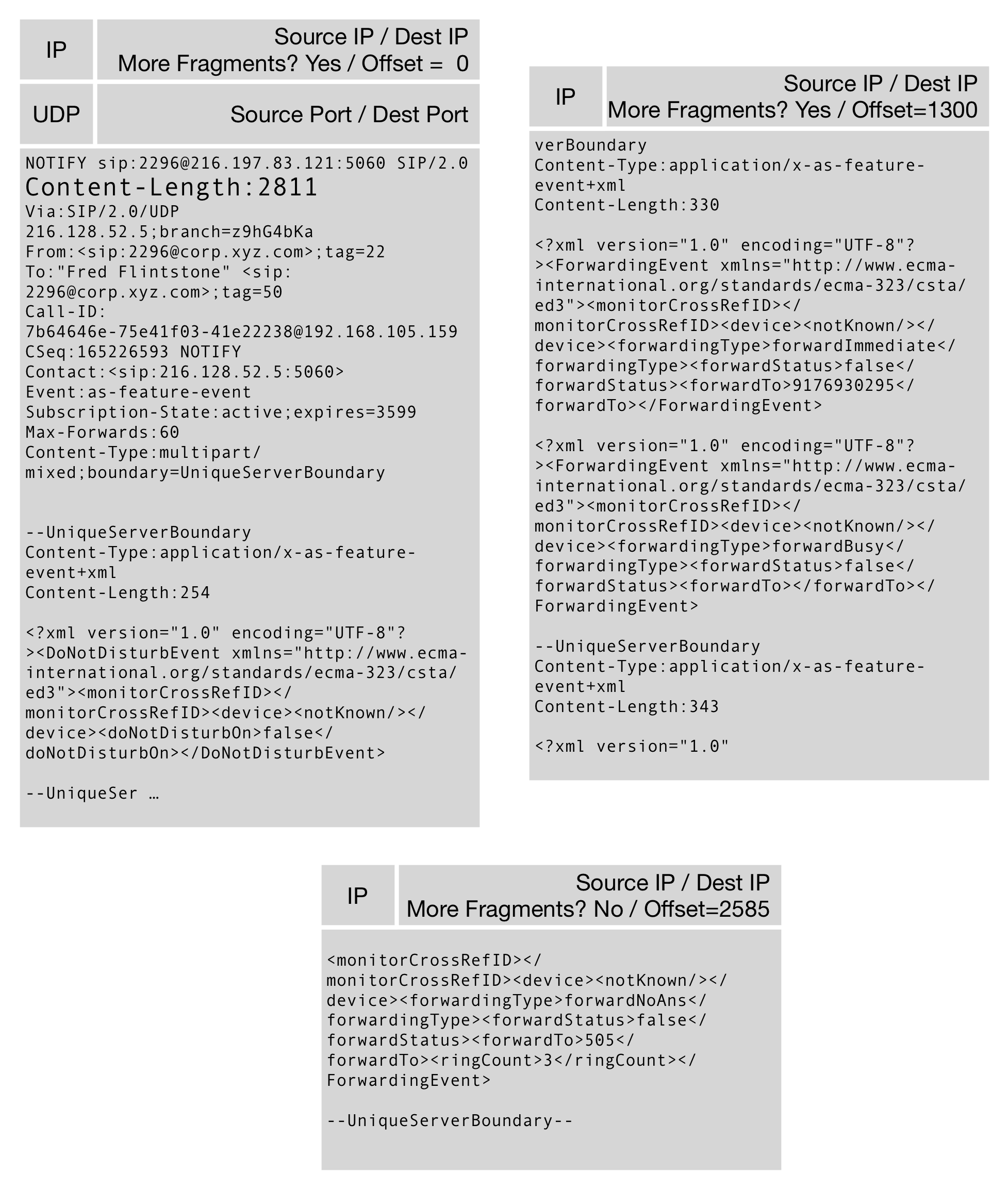 Figure 6. Sending a Large SIP message via UDP, like this one with 2811 bytes of payload and perhaps 500 bytes of headers, will cause fragmentation. All of the fragments have to be received for any of them to be useful.
Figure 6. Sending a Large SIP message via UDP, like this one with 2811 bytes of payload and perhaps 500 bytes of headers, will cause fragmentation. All of the fragments have to be received for any of them to be useful.Routing, Switching, Fragmenting
The Internet Protocol Standard requires that routers perform fragmentation. Fragmentation is often worse going through non-standards-compliant Layer 3 Switches. These devices can often do some of the functions of Routers, but not quite all. For example, the Cisco Catalyst 3750 can route packets, but cannot perform fragmentation in some MPLS scenarios, and cannot signal that it cannot fragment. This results in MPLS VPNs with blackholes for certain packets. With SIP, this appears when some SIP messages are delivered while others are dropped silently by the network. And it's hard to know just how much overhead the MPLS network will take because the MPLS size depends on the exact MPLS path in use at that moment.
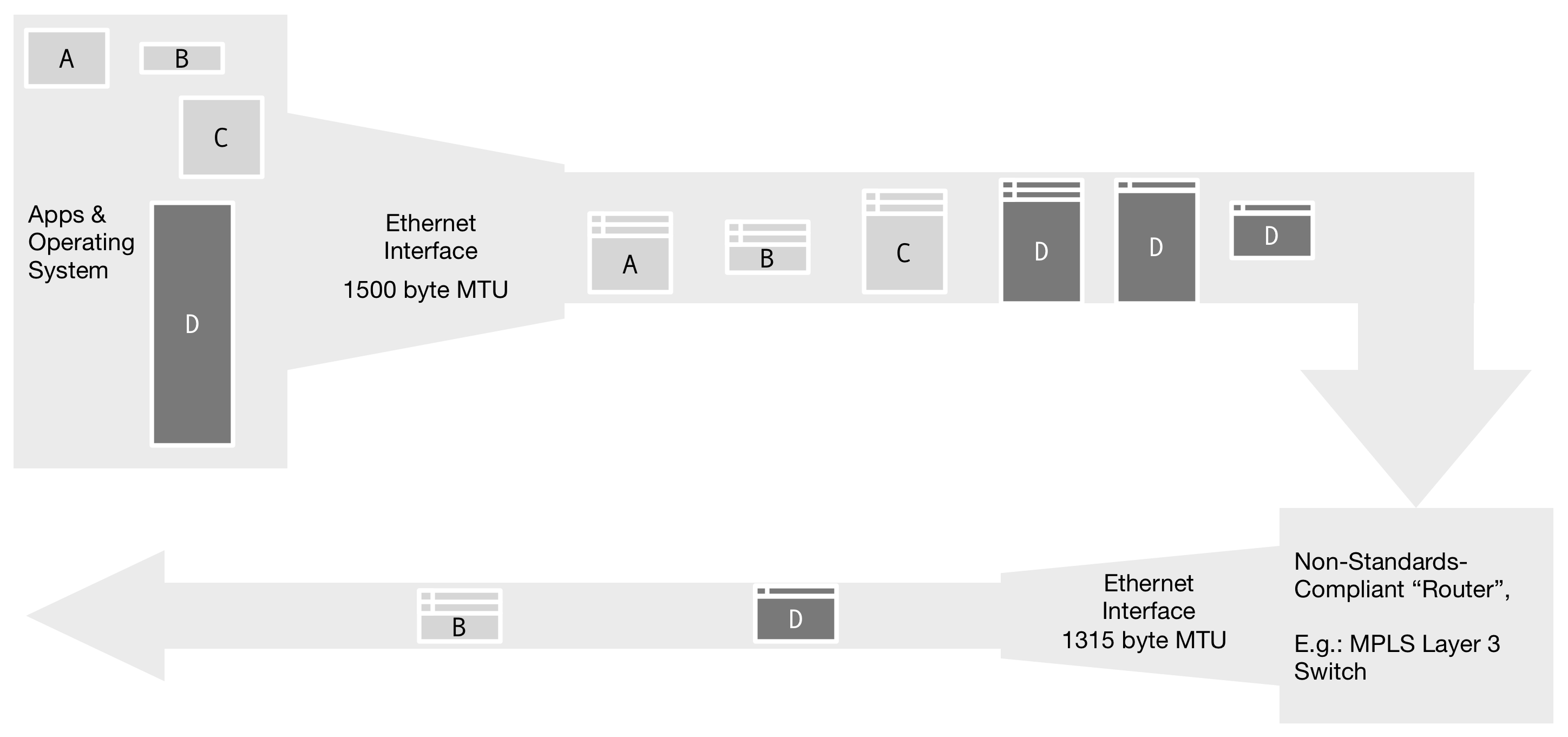 Figure 7. Some "router"-like devices refuse to perform IP fragmentation in violation of RFC 1812. A common scenario occurs when a "Layer 3 Switch" needs to transmit a 1500-byte frame to a link with MPLS overhead. Because the resulting frame of 1518 bytes is too large to be transmitted, the frame is silently dropped.
Figure 7. Some "router"-like devices refuse to perform IP fragmentation in violation of RFC 1812. A common scenario occurs when a "Layer 3 Switch" needs to transmit a 1500-byte frame to a link with MPLS overhead. Because the resulting frame of 1518 bytes is too large to be transmitted, the frame is silently dropped.
Some IP Routing/Switching fragments devices along the path reassemble IP datagrams from fragments. For example, the Cisco ASA firewall has a fragment buffer, allowing only 200 fragments awaiting reassembly, by default.
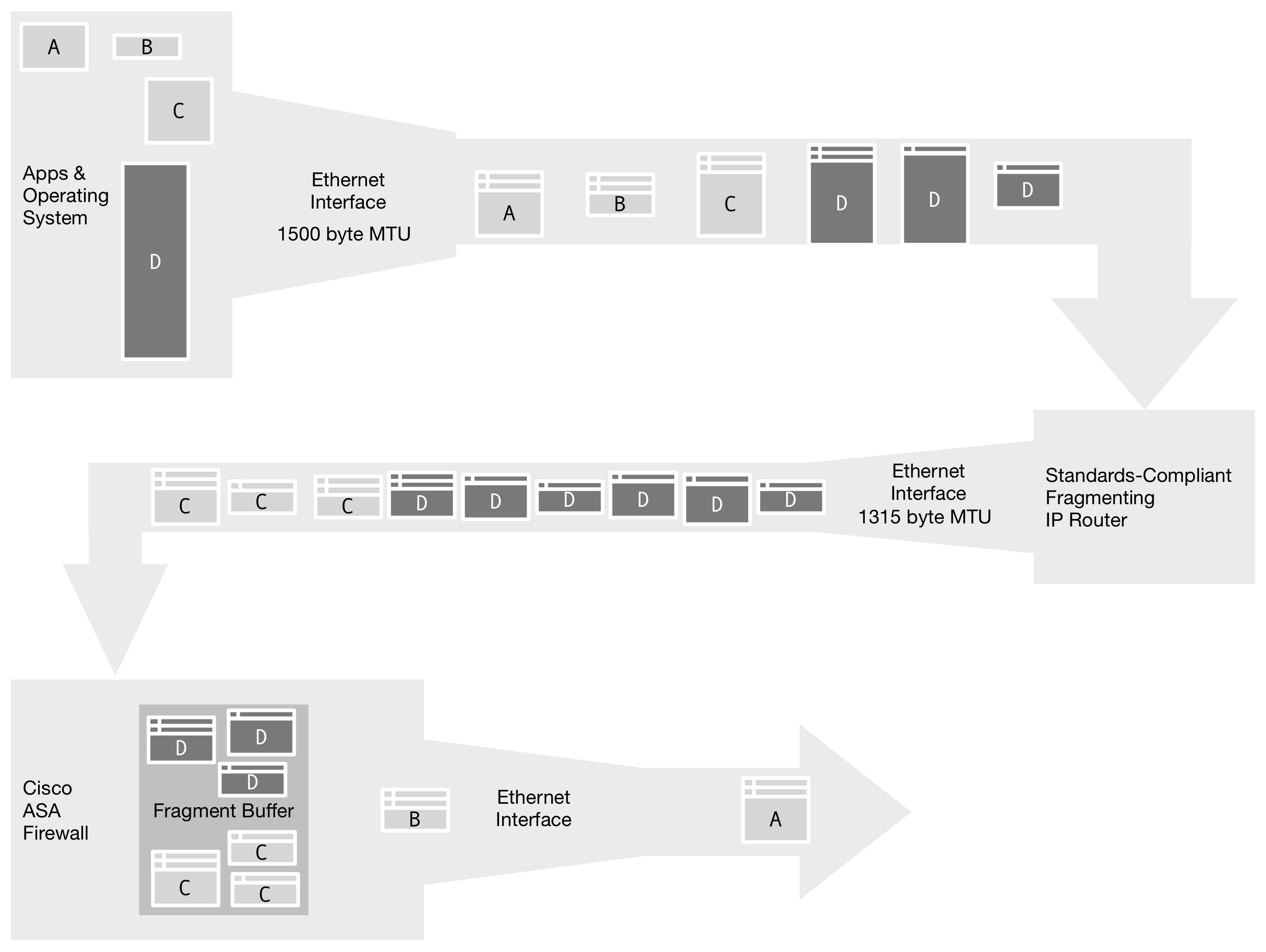 Figure 8. The Cisco ASA reassembles incoming fragments to perform packet analysis on the complete IP datagram to enforce security policy, storing them in a fixed-size buffer. Any fragments that overflow the buffer are discarded. For SIP, this requires retransmission of the entire SIP message.
Figure 8. The Cisco ASA reassembles incoming fragments to perform packet analysis on the complete IP datagram to enforce security policy, storing them in a fixed-size buffer. Any fragments that overflow the buffer are discarded. For SIP, this requires retransmission of the entire SIP message.The buffer limitations in these devices can be a real problem. The 200-fragment capacity of a Cisco ASA5500 can easily be overwhelmed by normal traffic of thousands of SIP phones. (Add this as a reason data firewalls create trouble with large-scale VoIP deployments.)
Session Border Controllers and Fragmentation
Some versions of the market leading Session Border Controller, the Oracle Acme Packet SBC, has limitations on handling fragments. The "Traffic Manager" from the Network Processors to the CPU controls the rate that IP fragments are delivered from the network to the CPU in the popular 4250, 3800 and 4500 platforms. Terry Kim has a great depiction of the traffic manager for the Oracle Acme Packet SBC. He highlights that the Oracle Acme Packet SBC handles fragmented SIP as "untrusted" traffic -- so if trusted endpoint devices, like customers, are sending fragmented SIP regularly, then the SBC doesn't provide them the same capacity that they would have if they were sending non-fragment capacity.
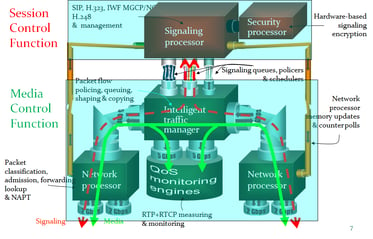 Figure 9. The Oracle Acme Packet SBC's "Intelligent Traffic Manager" regulates traffic, including fragments, to the Signaling Processor. Diagram: Terry Kim.
Figure 9. The Oracle Acme Packet SBC's "Intelligent Traffic Manager" regulates traffic, including fragments, to the Signaling Processor. Diagram: Terry Kim.The Oracle Acme Packet SBC was designed in an era that believed SIP over TCP would become more dominant, so that fragmented UDP should be rare. But the single rate limit for SIP fragmented traffic can be a real performance limitation when fragmented SIP becomes very common.
The Metaswitch Perimeta was designed much later, after the industry discovered that most SIP is still operating over UDP. The Perimeta was designed for fragmented SIP to be very common.
TCP: Segments over Fragments
The SIP standard, RFC 3261 mandates that TCP should be used to prevent fragmented SIP. Indeed, SIP over TCP does solve many of the problems by replacing IP fragmentation with TCP segmentation.
TCP segments slice up the stream of SIP messages into neat segments that fit within MTUs. Critically, TCP provides a fast and efficient mechanism for filling in gaps in the stream. Contrast this to IP fragmentation, where the entire SIP message must be re-sent any time one segment is lost.
However, a commonly-encountered problem using SIP/TCP is in limitations of Highly-Available Session Border Controllers, where the TCP synchronization and retransmission mechanism means that the state of any SIP/TCP connection may not be efficiently replicated to the standby SBC. For example, if SBC-A is active, then reboots, the SIP Phone using TCP typically has to reconnect to SBC-B. The SIP phone has to detect that the link to SBC-A has been lost. Both the Oracle Acme Packet SBC and the Metaswitch Perimeta SBC transmit a TCP RST (Reset) message when possible to notify the SIP phones that they need to re-register.
When using SIP/UDP, the failover to SBC-A to SBC-B can be a non-event: the IP address in use simply moves from one SBC instance to another because both SBC units in the pair know all of the state of the SIP registrations, subscriptions, and phone calls to all endpoints. But with SIP/TCP, the re-registration storm can be substantial, and disruptive. Imaging a network of 50,000 endpoints, all forced to re-register each time you reboot a single SBC instance.
The Fragments Are Coming
If you operate basic SIP trunking, or even some forms of today, you might not experience a lot of problems with fragmentation. But you should expect messages are growing larger, especially with integration of Fixed and Mobile networks, and the large SIP messages of IMS networks. How do you test? Send big SIP messages!
Michael Dell (Metaswitch) sums up the state of the art:
SIP messages are only getting bigger, so it is something you need to design and test for now, or it will be a major headache when it does happen. ... That could involve pro-active pressure testing to find and resolve the problem areas before they bite you for real, and also monitoring largest message sizes flowing around your network so that you can predict when you’re going to start seeing more fragmentation and act accordingly.
